I am part of a group of people who decided to fork Camunda 7, an open source BPMN engine for Java and other languages, in October. This was in response to Camunda’s announcement of the engine’s end of life in 2025. We are convinced that the technology is still useful for many people and that Camunda has built a robust engine, so we announced Operaton as a community-driven fork to keep it alive in the future.
The Job Executor
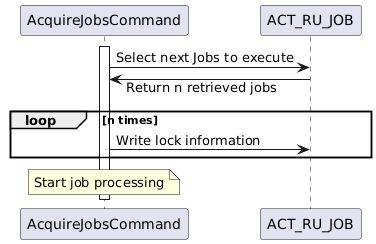
One of the most criticized aspects of the engine is the way the job executor works. Operaton will put all jobs which have to be picked up by the process engine into a single table, ACT_RU_JOB with the following structure:
create table ACT_RU_JOB (
ID_ varchar(64) NOT NULL,
REV_ integer,
TYPE_ varchar(255) NOT NULL,
LOCK_EXP_TIME_ timestamp,
LOCK_OWNER_ varchar(255),
EXCLUSIVE_ boolean,
...
PRIORITY_ bigint NOT NULL DEFAULT 0,
...
LAST_FAILURE_LOG_ID_ varchar(64),
BATCH_ID_ varchar(64),
primary key (ID_)
);
If you are scaling Operaton horizontally by adding new nodes and pointing them to the same database, all these nodes will query this table for the n latest jobs, retrieve them and lock them. This will not be achieved by row level locks in the database but by setting a logical lock by updating the table after fetching the rows:
protected void lockJob(AcquirableJobEntity job) {
String lockOwner = jobExecutor.getLockOwner();
job.setLockOwner(lockOwner);
int lockTimeInMillis = jobExecutor.getLockTimeInMillis();
GregorianCalendar gregorianCalendar = new GregorianCalendar();
gregorianCalendar.setTime(ClockUtil.getCurrentTime());
gregorianCalendar.add(Calendar.MILLISECOND, lockTimeInMillis);
job.setLockExpirationTime(gregorianCalendar.getTime());
}
This means that two job executors could theoretically retrieve the list – which happens, if there are many concurrent process engines querying for the same table. If this happens, there is an instance of org.operaton.bpm.engine.impl.db.entitymanager.OptimisticLockingListener registered, which will remove the acquired job from the list of results if such a collision happens. In high load scenarios it is possible that all returned rows from a job query are already being processed, meaning no work will be done in one cycle.
Trying to optimize for a higher workload
The strategy for querying these jobs can be adjusted with parameters, and some weeks ago an interesting question was asked in our Operaton forum by Jean Robert Alves, a software architect working with Camunda 7. Anticipating a high workload they will have to deal with in the nearer future he was trying to tune the job executor to his needs. He had a great test setup and was able to tune and compare different configurations in terms of execution time. The results were less than ideal, confirming the preconception I mentioned earlier about the performance of the job executor at scale.
Now that we have forked the engine and can set the roadmap and implement new features, I was curious if there was a way to improve this locking situation with plain SQL. The engine supports multiple RDMBSs, but the queries are implemented as plain SQL with MyBatis and it would be possible to modify and optimize them, even with different tweaks for different database vendors, if necessary.
Since the instance discussed in this thread was running on PostgreSQL I was reading documentation and discovered the SKIP LOCKED clause in the paragraph about locking mechanisms:
With SKIP LOCKED, any selected rows that cannot be immediately locked are skipped. Skipping locked rows provides an inconsistent view of the data, so this is not suitable for general purpose work, but can be used to avoid lock contention with multiple consumers accessing a queue-like table.
This sounded like exactly what we needed: Every query to the job executor table now omits rows which are already locked from the result set, and if an Operaton instance wants to query 10 jobs for execution, they will retrieve the next 10 jobs which are already locked. In a quickly hacked Camunda instance, Jean Robert was able to confirm performance improvments from 40 minutes down to 16 minutes. The same syntax also works for MariaDB, MySQL and Oracle DB.
Implementing the feature in Operaton
I started implementing this feature in Operaton, you can already try it out by building Operaton from this branch. Properties can be passed through by Spring Boot properties, other environments were not implemented or tested yet.
The two questions we need to answer before including this as an (opt in) feature for the engine for everybody are:
- Some supported databases don’t support this syntax, IBM DB2 and MSSQL. Is there another way to achieve this, or will users of those databases be left out? DB2s “SKIP LOCKED DATA” clause and MS SQLs “UPDLOCK / READPAST” feature look similar, but need to be evaluated.
- Testing, testing, testing. While we plan to create a feature flag to enable this behavior, we need to make sure it provides the quality a process engine needs
I’m looking forward to receive feedback from people using this feature in real-world settings and I’d be excited if this feature made the engine perform better for certain usecases.
Outlook
If you are interested in this topic you are welcome to subscribe to our forum or watch the issue on GitHub.